最近对逆向感兴趣, 看了几天视频还有论坛逆向贴, 然后就找了个在线视频的站点练手
因为是初学者,所有帖子可能有点冗长...
帖子最后会请教几个逆向过程中遇到的问题,大佬们路过的话请帮忙解惑, 感谢
-----------------------------------------------------------
帖子大致流程:
01. 找到m3u8链接
02. 分析m3u8生成链接
03. AES解密链接
04. 去除ts文件的图片伪装头
05. 用python代码实现自动下载思路
06. 逆向过程中遇到的问题(问题已有大佬解答)
-----------------------------------------------------------
1.1:
逆向目标 aHR0cHM6Ly9nYXplLnJ1bi9wbGF5LzNmNDhiZWRjMTI1MGE1NWFjMzM0NWU1MGIzYmY3Yjhi
用chrome打开链接后按F12打开开发者工具并切换到Network选项卡, 随便拖动一下进度条, 发现有好多jpg
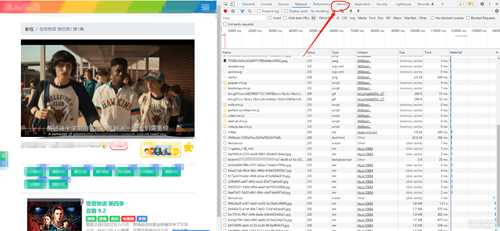
哎? 这里肯定可以猜得出来这货是装的, 他肯定是ts视频文件
随便找一个右键-新窗口打开, 好像还真是一张图片? 右键把他另存到本地后缀改成.ts然后用potplayer打开,也是图片...
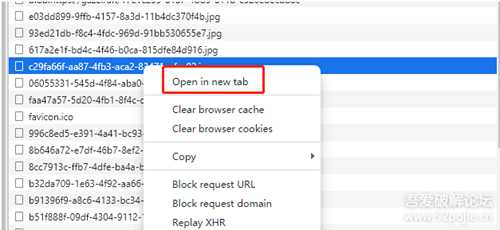
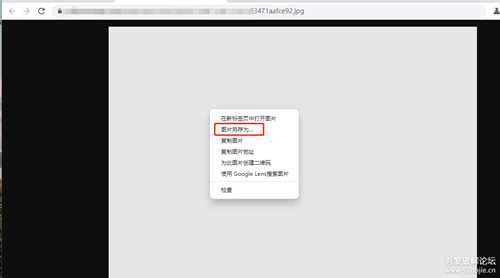
装的还挺像, 反正他一定是ts文件, 后来想起站内大佬的帖子
https://www.52pojie.cn/thread-1618559-1-1.html
可能是加了图片头进去, 按照帖子里的方法,下了winhex打开
一个正常的ts文件和这个下载好的图片, 然后ts文件开头是G@,两站图对比了一下后发现下载的jpg文件比正常的ts文件多出了蓝色选中位置的区域

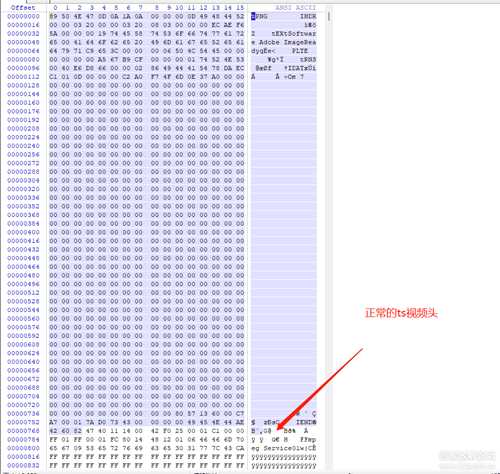
右键把这块区域删了在另存, 再用potplayer打开后果然可以正常打开了
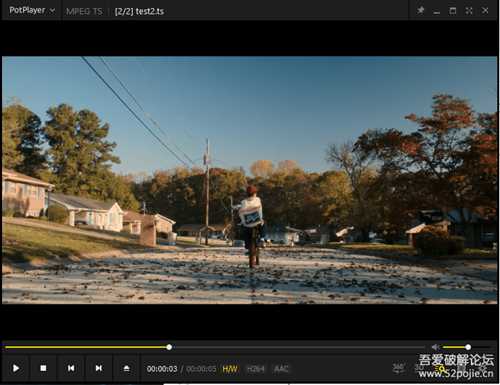
1.2:
接下来找一下m3u8文件, 在过滤这里输入m3u8, 发现什么都没有??? 多刷新几次网页还是没找到m3u8, 仔细观察可以发现每次ts文件被加载前都会先请求一个 "1+gazes_v-@_info",右键-新窗口打开,又是一张图片??刚被骗过一次之后这次聪明点,直接拉到winhex看看是啥玩意,这不是标准的m3u8文件吗? 改个后缀为.txt再用记事本打开, m3u8文件搞定
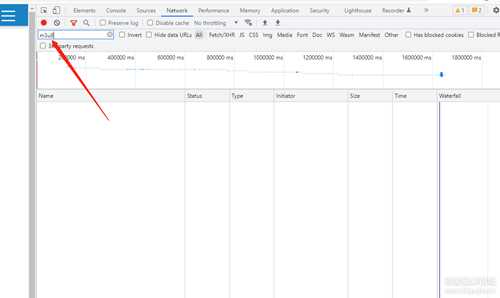
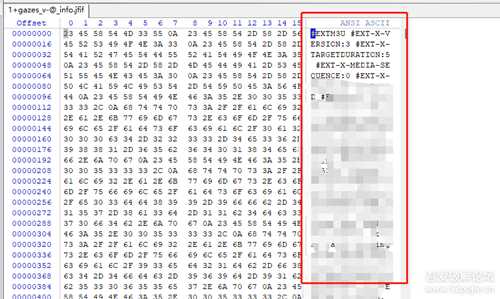
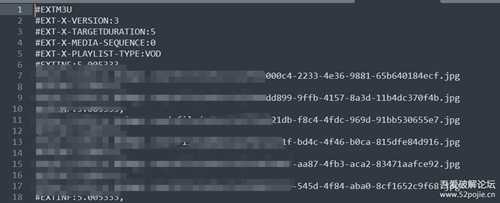
2.1:
右键1+gazes_v-@_info复制链接把下载地址复制起来,把整个链接搜索无结果,搜索文件名也是无结果,最后再短一点用@_info搜索到了一些可疑的代码
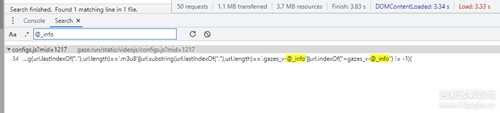
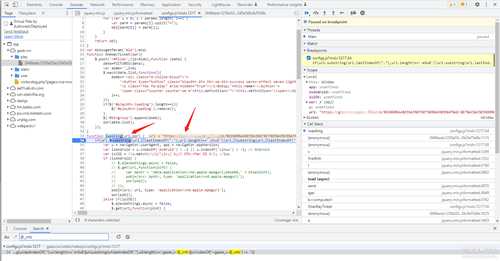
这段代码用来判断链接后缀是否为m3u8或者@_info,点进去下个断点重新刷新网页,断点生效了,这里的url值就是m3u8的下载链接, 从右边的调用堆栈里跟一下,看看这个链接是哪里来的,从图片里很明显可以看到js发起了一个post请求,然后响应的data里就有我们需要的m3u8链接
去Network标签里搜索一下"/mfiles" 试试, 点开看看请求的返回结果里的src,怎么变成一串看不懂的东西了?
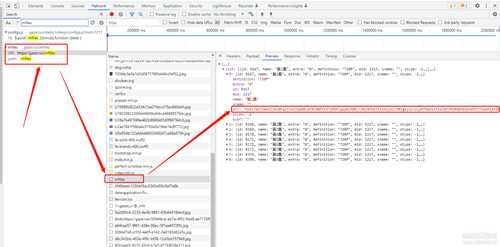
刚才上一张图看还是一个网址(分析到这里卡了一段时间),后来查了才知道
function (data) {data=PICTURES(data);...}
这里是一段回调函数, 就是把请求回来的结果(data)直接丢进去这个函数里执行, 这里可以看到data被重新赋值了
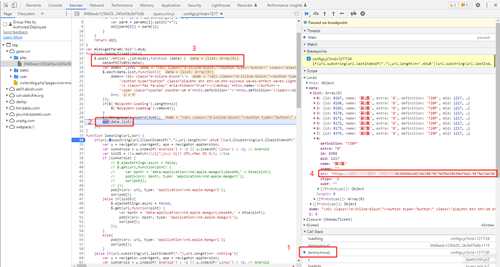
赋值的内容为PICTURES(data),只要知道 PICTURES 这个函数对响应的数据做了什么操作,就可以了, 全局搜索一下 PICTURES, 找到加密函数了,代码量非常少而且没有混淆, 很明显看得出来是 用AES加密,模式为CBC
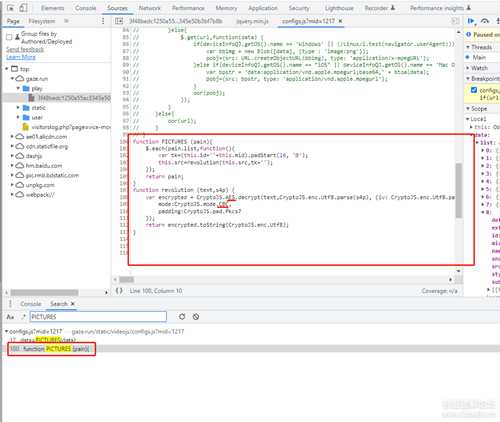
这次用的是python脚本,AES平时都没用过,所以我也不知道怎么写,直接Google 查一下看看怎么用,补完AES内容之后, 现在解密数据需要一个16字节的key和IV偏移量,需要解密的内容为那串看不懂的url值
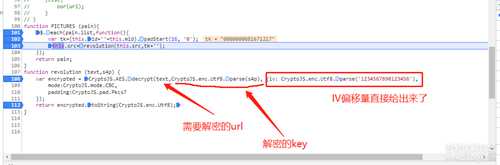
2.2:
PICTURES这个函数把需要解密的url和tk的值传给了revolution, 从revolution明显看得出来tk其实就是解密的key,AES的IV值(1234567890123456)已经直接给出来了,那解出key值就大功告成了
2.3:
tk=(this.id+''+this.mid).padStart(16, '0'), 鼠标放上去,可以看到mid的值为1217
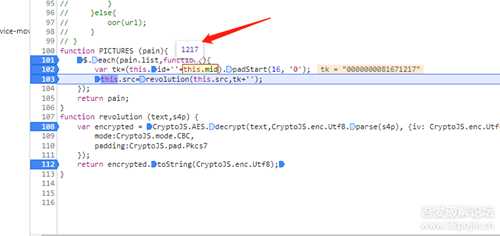
2.3.1:
源代码里直接搜一下mid试试看,运气非常好, mid的值直接在网页源代码里给出来了
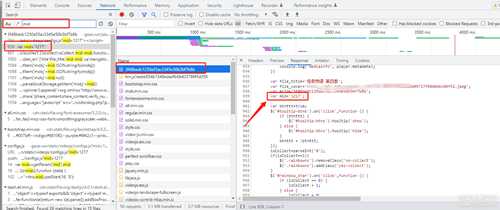
2.3.2:
id的值也用同样的步骤,鼠标放上去看出来是8167
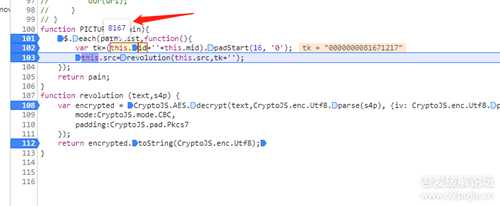
搜一下id试试看,结果非常非常非常多,换个姿势,搜索一下8167, id的来源也找出来了
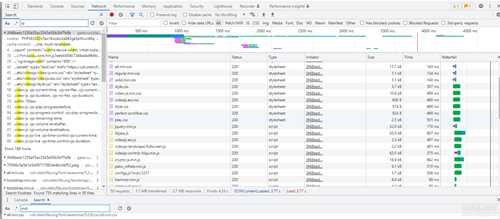
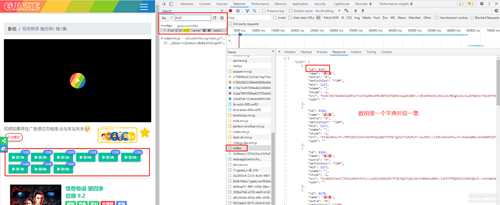
id值在请求mfiles的时候就已经和被加密的url一起给出来了, 这个mfiles请求回来的内容为一个数组,一个数组就是一集电视剧的信息, 每一个url解密的时候各自对应一个id,现在mid和id都解出来了
2.3.3:
那后面的padStart(16, '0')是啥玩意? JS不太懂,直接查一下
发现这就是用来字符串补全的,就是说id和mid加起来没有16个字符的话,就用0补在前面,直到你够16个, 为什么? 查了一下是因为AES的key一定要16位, 那python怎么实现补零呢? 也不太熟,继续查,方法很多, 这里用
str.rjust(width,'0') 来实现,记住,是左补零不是右补零,不要乱来.
3.1:
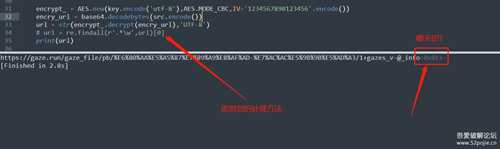
来用python实现一下这个解密, 先用现有的密文和key,IV来试试,看结果是不是和浏览器解密出来的一致
示例代码图片:
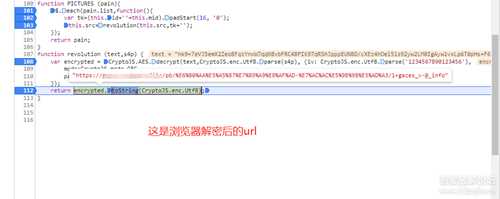
(不要问我为什么要把key和IV重新编码,也不要问为什么要先base64解码密文,因为我也一直报错一直改的,要decode和encode也是抄别人的...)
结果是没问题的, url一致
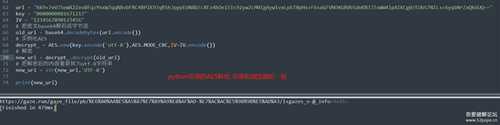
4.1:
在windows有现成的软件winhex来右键删除伪装的图片头, 用python来实现的话因为之前没有处理过类似问题,所以完全没头绪,发帖问了大佬才知道可以在使用requests下载来的时候用角标范围来截取,类似 requests.get(url).content[index:]
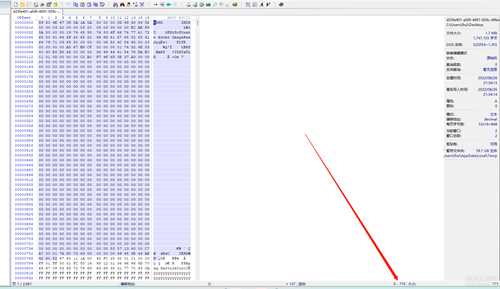
那切多少合适呢? 去浏览器随便找一个ts片段下载下来改个名字为1,丢进去winhex,然后把需要删除的圈起来,右下角可以看到显示了多少, 0-770
那我们需要的就是771往后的所有数据了, 试着操作一下,实例代码:
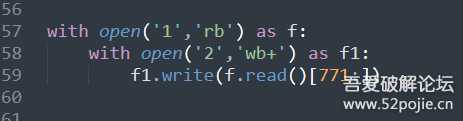
然后把切好出来的2放进去winhex看看,G@开头,这是ts文件的文件头,放进去potplayer试试看,也能正常播放.
5.1:
想要用python实现下载视频需要获取以下值
1. 向"/mfiles"发起一个post请求来获取被加密的m3u8下载地址, 但是这个请求需要一个mid参数.
2. mid的值在2.3.1里已经说了在网页源代码里了, 可以直接用re正则匹配出来, 至此加密的链接已经拿到.
3. 接下来解密url需要获取解密的key和IV, 2.2里说过了,IV是定值"1234567890123456",直接给出来了
4. key就是2.3里的tk, 需要用到id和mid, mid在上面已经拿到了,id 在2.3.2里说了可以在"/mfiles"的返回值里
5. 以上所有信息拿到之后就可以愉快的开始下载了, 源代码会放在帖子末尾供参考.
6.1:
以下是这次遇到的问题,大佬路过的话望不吝赐教:
问题1由 9楼的 @hecoter 、13楼的 @4028574 、18楼的 @0x783A 协助解决
问题2由 19楼的 @0x783A 协助解决
多谢以上四位大佬。
脚本就不修改了,毕竟只是提供一个思路,有兴趣的自己动手改。
1. 我想要知道浏览器拿到ts文件的时候是怎么去除文件头的? 这个实现的过程我找不到, 我也看不到他的回调函数,我需要知道他到底切了多少字节的数据,因为这个站有点奇怪,有些ts切片他们在前面加的图片头,有的不加,有的加的量还不一样,所以这个切多少我不能写死.
2. 为什么我解密出来的链接有一个<0x01>这个东西? 如果我不处理直接用requests请求的话会报错,目前能想到的方法就是用re把他剔除掉,为什么会产生这个?怎么优雅的去除掉?
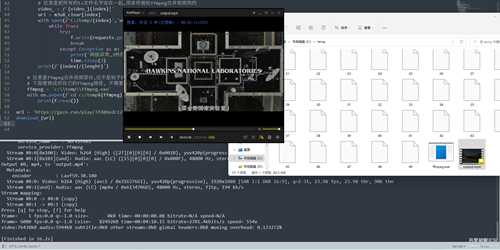
下面提供一下我写好的, 使用的话需要注意:
1. 所有下载的ts文件都会下载放在c:/temp/ 下面并且需要你自己删除
2. 如果本地开了代{过}{滤}理的话,记得修改打开脚本的代{过}{滤}理
3. 因为下载视频不是目的,主要是学习逆向, 所以默认就下载50个ts来合并(lenght = 50), 如果你真的需要全部下载, 把这个注释取消掉就是全部下载了 lenght = len(m3u8_clear)
4. 如果要合并视频的话, 你要自己下载好ffmpeg然后配置好路径, 具体看脚本末尾, 如果不需要就把三行全部注释掉
5. 为什么不用多线程下载? 站内有逍遥大佬的m3u8下载器为什么不用? 为什么只能下载第一集, 不能下载后面的几集? 因为下载视频并不是最终目的, 我就是想学习下逆向
6. 脚本不是全站通用的, 因为这个站有点怪, 有些他会加入伪装(需要我们切除), 有些他不加, 所以不通用, 如果完整看完帖子的话, 我想你应该知道怎么修改脚本的~~
[Python] 纯文本查看 复制代码
import requestsimport reimport timeimport base64from Crypto.Cipher import AESimport osimport json# 这里是代{过}{滤}理设置,看具体情况选择是否开启os.environ["http_proxy"] = "http://127.0.0.1:10791"os.environ["https_proxy"] = "http://127.0.0.1:10791"def download_(url): page = requests.get(url) mid = re.findall(r'mid=\'(\d+)\'',page.text)[0] post_url = 'https://gaze.run/mfiles' # 这里必须给一个请求头,不然拿不到数据 res = requests.post(post_url,data={'id': mid},headers={'x-requested-with':'XMLHttpRequest'}) res_dic = json.loads(res.text) src = res_dic['list'][0]['src'] id_ = res_dic['list'][0]['id'] # id + mid 用0向前填充至16位 key = f'{id_}{mid}'.rjust(16,'0') encrypt_ = AES.new(key.encode('utf-8'),AES.MODE_CBC,IV='1234567890123456'.encode()) encry_url = base64.decodebytes(src.encode()) m3u8_url = str(encrypt_.decrypt(encry_url),'UTF-8') # 用re去除非链接字符,这个问题等站内大佬解答 m3u8_url = re.findall(r'.*\w',m3u8_url)[0] m3u8 = requests.get(m3u8_url).text # 清除m3u8里非链接的行 m3u8_clear = re.sub(r'#EX.*','',m3u8) m3u8_clear = m3u8_clear.split() # 因为是下着玩的,没必要全部下载,这里只获取前50个ts文件就行了 lenght = 50 # lenght = len(m3u8_clear) video_ = '' for index in range(lenght): # 这里是把所有的ts文件名字连在一起,用来传递给ffmpeg合并视频用的 video_ = f'{video_}{index}|' url = m3u8_clear[index] with open(f'C:/temp/{index}','wb') as f: while True: try: f.write(requests.get(url,timeout=10).content[770:]) break except Exception as e: print('网络异常,3秒后重新下载') time.sleep(3) print(f'{index}/{lenght}') # 这里是ffmpeg合并视频部分,这不是帖子的重点,所以就不多说了,有兴趣自己去搜索相关内容 # 下面替换成你自己的ffmpeg路径, 不需要合并就下面三行代码都注释掉 ffmpeg = 'c:\\temp\\ffmpeg.exe' with os.popen(f'cd c:/temp&{ffmpeg} -i "concat:{video_}" -c copy output.mp4') as f: print(f.read())url = 'https://gaze.run/play/3f48bedc1250a55ac3345e50b3bf7b8b'download_(url)
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件!
如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
暂无“逆向分析某影视m3u8链接下载视频(初学者的第一次逆向)”评论...
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新动态
2025年12月14日
2025年12月14日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]