很多刚开始做SEO的朋友经常问到的一个问题就是,搜索引擎到底是怎样抓取文章内容的,它的收录原则大概是怎样,首先声明:一下方法均为本人经验总结,并非官方给出的抓取原则。下面我来简单说一下:
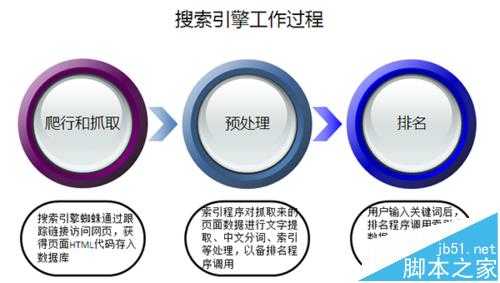
1、抓取:
这一步是搜索引擎录入数据的工作,它是怎样进行的呢?例如百度,百度每天会分配大量蜘蛛程序在浩瀚无边的互联网世界中爬行抓取,作为一个新站的站长,你必须要清楚的是,如果网站刚刚建立,百度如何知道你的网站呢,所以这就有了引蜘蛛的说法,我们在建站初期要多发点连接或者和别人的网站交换连接,这样做的主要目的就是引蜘蛛过来抓取我们的网站内容。
当蜘蛛程序抓取到内容后它不进行任何处理先是存储到一个临时的索引库里面,也就是说这部完成以后的内容是乱七八糟,什么内容都有的,不过蜘蛛程序还是会进行合理分类的,方便下一步的过滤工作。

2、过滤:
当第一步完成以后,蜘蛛程序就会开始进行过滤工作,当然这些步骤实际情况下可能是同时进行的,我们只是来分解它的原理而已。搜索引擎会根据抓取到内容的优劣程度进行筛选,去除劣质没用的留下精华有用的,这就是过滤工作,当然这些工作的处理过程都是比较快的,因为数据处理时效是搜索引擎主要研究的问题。
3、存储:
然后搜索引擎就会将优质的内容以某种算法索引存储在自己的硬盘空间中方便后期用户的所以调用,也就是说到这里数据才是真真的收录到搜索引擎的数据存储空间中。

4、展示:
当用户搜索某个关键词时,搜索引擎会根据某种算法来所以数据库里面的内容展现给客户,这种展现索引速度非常快,大家可以看到,如果我们在百度随便搜一个词它能迅速展现出亿计的搜索结果,这也是搜索引擎的核心技术,它拥有非常快速的检索能力。
5、排名:
其实这一步很第四步是同时进行的,搜索引擎在给用户展现的同时已经对数据做出了排名,至于这个排名在搜索引擎内部是如何计算的属于内部机密,谁也不知道,我门只能是猜测它。做为搜索引擎公司来讲,它的核心技术就是抓取 筛选 检索 排名 展示 执行这些步骤需要的时间越短就证明它的技术越强大。

注意事项:
综上所述,我们应该理解为,搜索引擎公司就是在研究如何能快速的为用户提供想要的内容。
百度,收录
更新动态
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]